前言 其实一开始对栈、堆的概念特别模糊,只知道好像跟内存有关,又好像事件循环也沾一点边。面试薄荷的时候,面试官正好也问到了这个问题,当时只能大方的承认不会。痛定思痛,回去好好的研究一番。 我们将从JS的内存机制以及事件机制和大量的 (例子)来了解栈、堆究竟是个什么玩意。概念比较多,不用死读,所有的 心里想一遍,浏览器console看一遍就很清楚了。 let's go
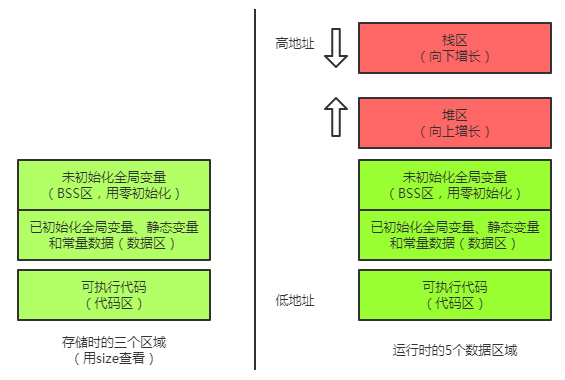
JS内存机制 因为JavaScript具有自动垃圾回收机制,所以对于前端开发来说,内存空间并不是一个经常被提及的概念,很容易被大家忽视。特别是很多不专业的朋友在进入到前端之后,会对内存空间的认知比较模糊。
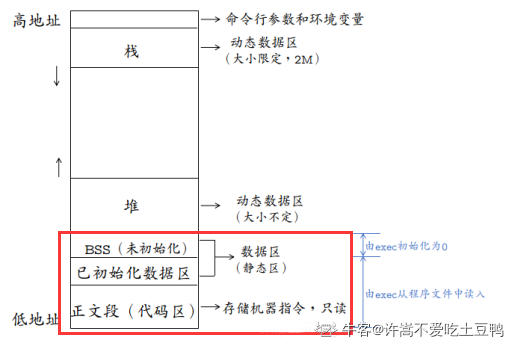
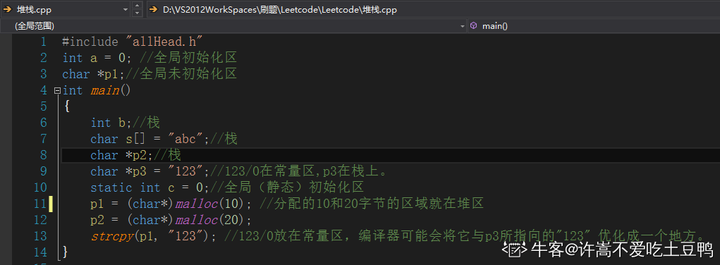
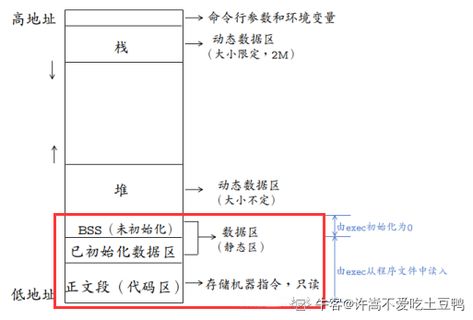
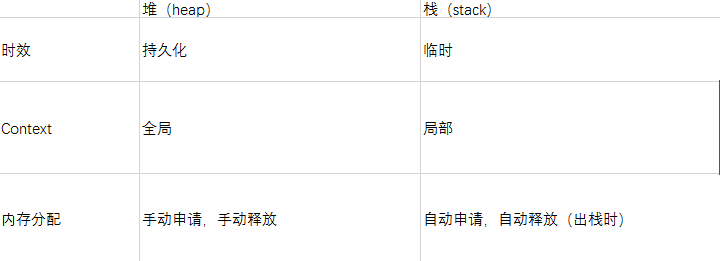
在JS中,每一个数据都需要一个内存空间。内存空间又被分为两种,栈内存(stack)与堆内存(heap) 。
栈内存一般储存基础数据类型 Number String Null Undefined Boolean
(es6新引入了一种数据类型,Symbol)
复制代码
最简单的 我们定义一个变量a,系统自动分配存储空间。我们可以直接操作保存在栈内存空间的值,因此基础数据类型都是按值访问。
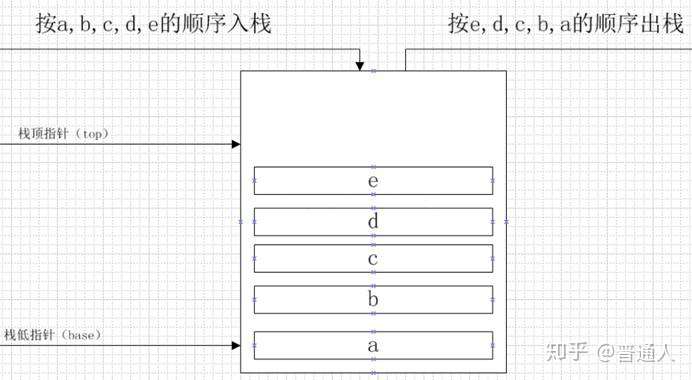
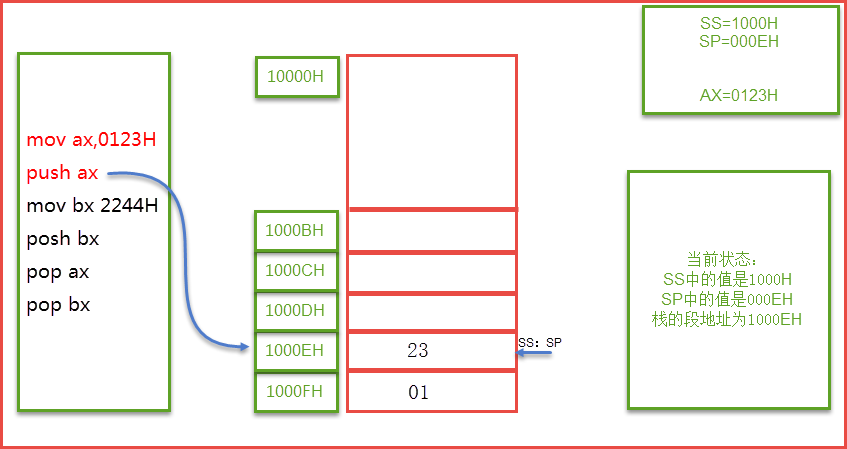
数据在栈内存中的存储与使用方式类似于数据结构中的堆栈数据结构,遵循后进先出 的原则。
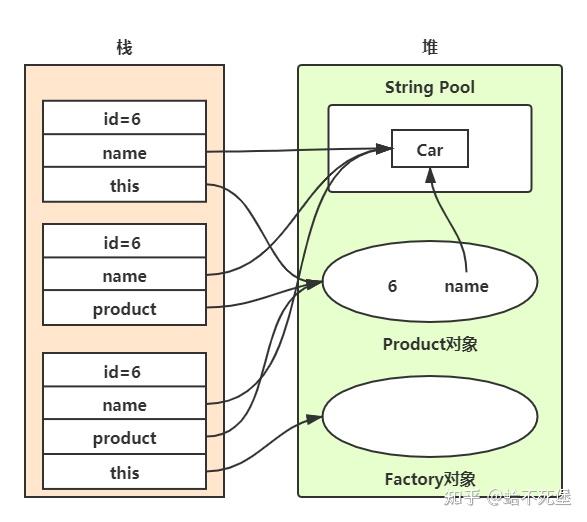
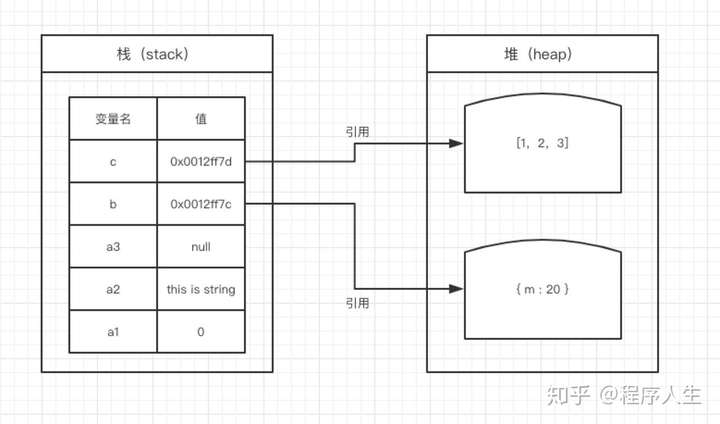
堆内存一般储存引用数据类型 堆内存的 与其他语言不同,JS的引用数据类型,比如数组Array,它们值的大小是不固定的。引用数据类型的值是保存在堆内存中的对象。JavaScript不允许直接访问堆内存中的位置 ,因此我们不能直接操作对象的堆内存空间。看一下下面的图,加深理解。
比较 
var a1 = 0; // 栈
var a2 = 'this is string'; // 栈
var a3 = null; // 栈
var b = { m: 20 }; // 变量b存在于栈中,{m: 20} 作为对象存在于堆内存中
var c = [1, 2, 3]; // 变量c存在于栈中,[1, 2, 3] 作为对象存在于堆内存中
复制代码
因此当我们要访问堆内存中的引用数据类型时,实际上我们首先是从栈中获取了该对象的地址引用(或者地址指针) ,然后再从堆内存中取得我们需要的数据。
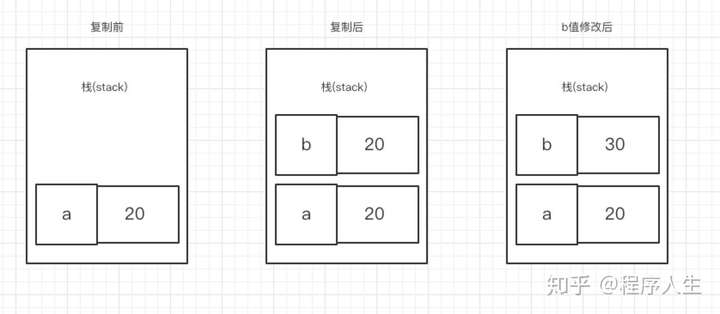
测试 var a = 20;
var b = a;
b = 30;
console.log(a)
复制代码
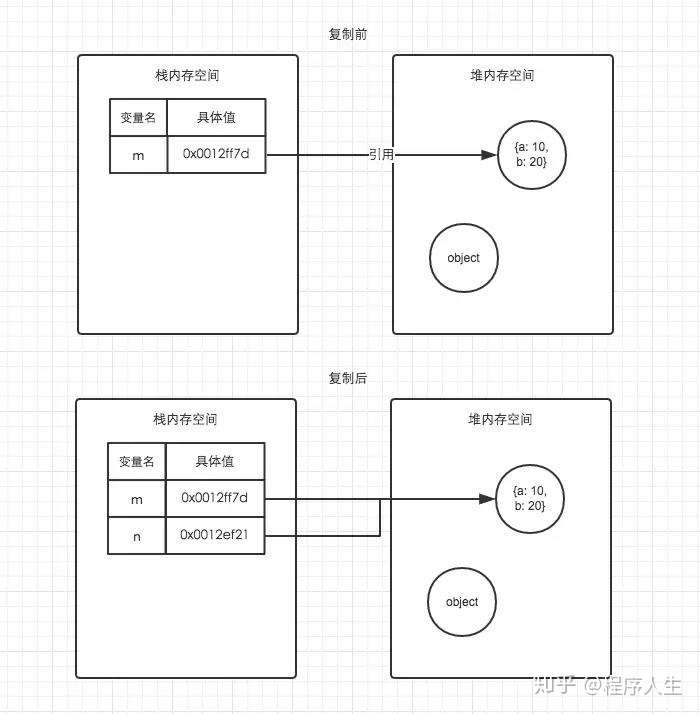
var m = { a: 10, b: 20 }
var n = m;
n.a = 15;
console.log(m.a)
复制代码
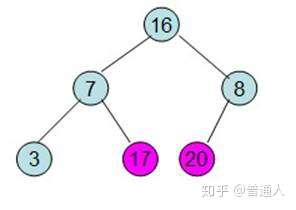
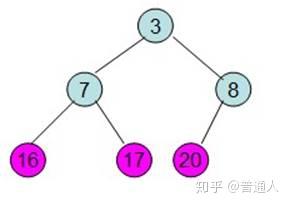
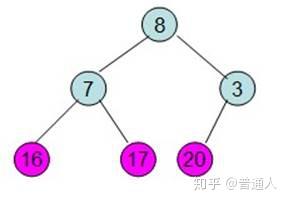
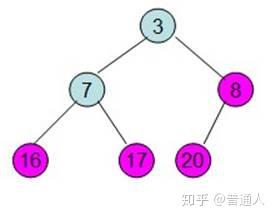
同学们自己在console里打一遍,再结合下面的图例,就很好理解了
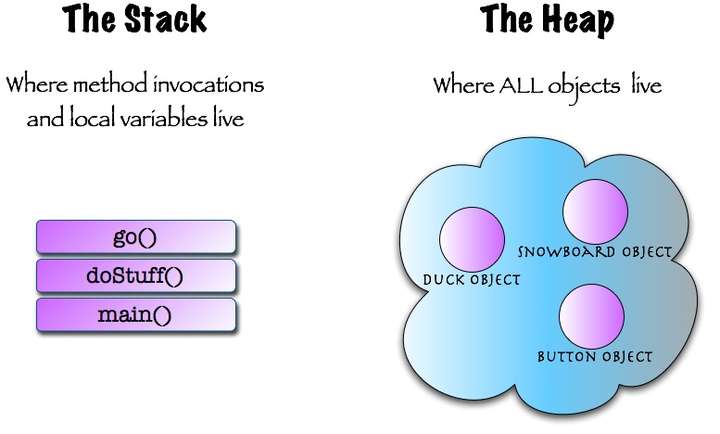
内存机制我们了解了,又引出一个新的问题,栈里只能存基础数据类型吗,我们经常用的function存在哪里呢?
浏览器的事件机制 一个经常被搬上面试题的 console.log(1)
let promise = new Promise(function(resolve,reject){
console.log(3)
resolve(100)
}).then(function(data){
console.log(100)
})
setTimeout(function(){
console.log(4);
})
console.log(2)
复制代码
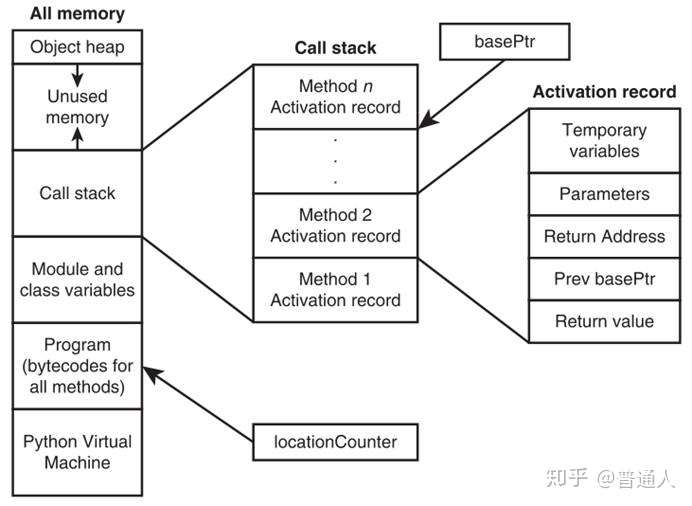
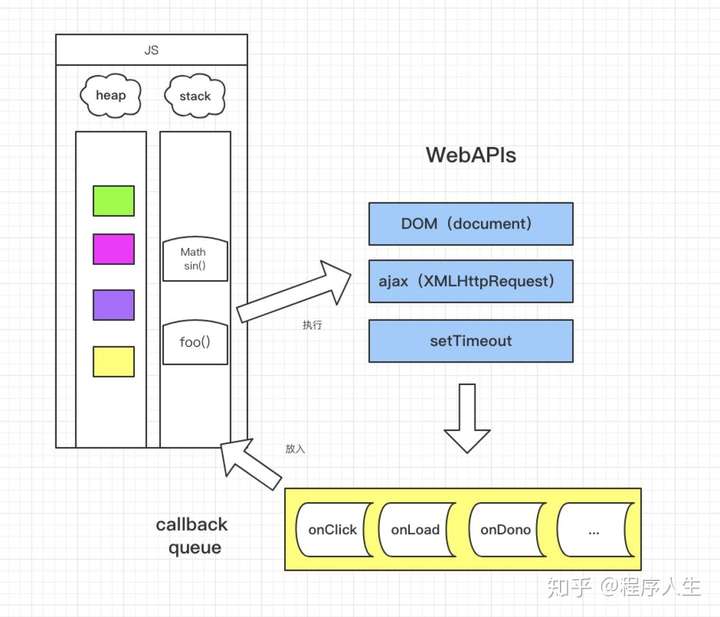
上面这个demo的结果值是 1 3 2 100 4 对象 放在heap(堆)里,常见的基础类型和函数放在stack(栈)里,函数执行的时候在栈 里执行。栈里函数执行的时候可能会调一些Dom操作,ajax操作和setTimeout定时器 ,这时候要等stack(栈)里面的所有程序先走**(注意:栈里的代码是先进后出)**,走完后再走WebAPIs,WebAPIs执行后的结果放在callback queue(回调的队列里,注意:队列里的代码先放进去的先执行),也就是当栈里面的程序走完之后,再从任务队列中读取事件,将队列中的事件放到执行栈中依次执行,这个过程是循环不断的。
1.所有同步任务都在主线程上执行,形成一个执行栈
2.主线程之外,还存在一个任务队列。只要异步任务有了运行结果,就在任务队列之中放置一个事件。
3.一旦执行栈中的所有同步任务执行完毕,系统就会读取任务队列,将队列中的事件放到执行栈中依次执行
4.主线程从任务队列中读取事件,这个过程是循环不断的
概念又臭又长,没关系,我们先粗略的扫一眼,接着往下看。
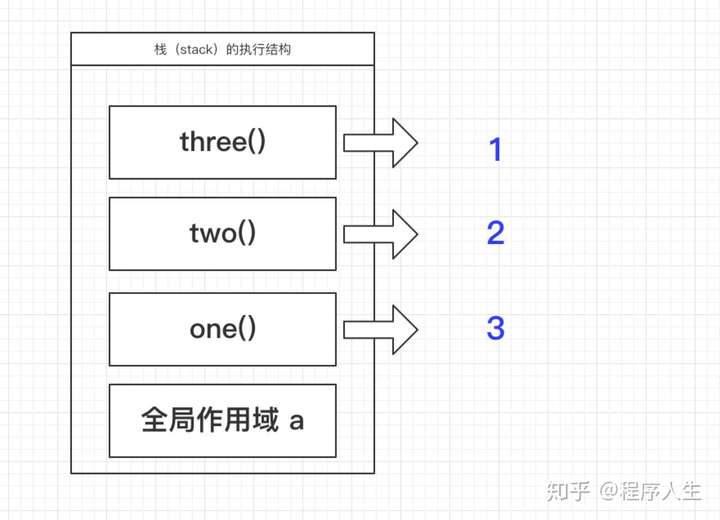
举一个 说明栈的执行方式 var a = "aa";
function one(){
let a = 1;
two();
function two(){
let b = 2;
three();
function three(){
console.log(b)
}
}
}
console.log(a);
one();
复制代码
demo的结果是 aa 2 图解
执行栈里面最先放的是全局作用域(代码执行有一个全局文本的环境),然后再放one, one执行再把two放进来,two执行再把three放进来,一层叠一层。
最先走的肯定是three,因为two要是先销毁了,那three的代码b就拿不到了,所以是先进后出 (先进的后出),所以,three最先出,然后是two出,再是one出。
那队列又是怎么一回事呢? 再举一个 console.log(1);
console.log(2);
setTimeout(function(){
console.log(3);
})
setTimeout(function(){
console.log(4);
})
console.log(5);
复制代码
首先执行了栈里的代码,1 2 5。 前面说到的settimeout 会被放在队列里,当栈执行完了之后,从队列里添加到栈里执行(此时是依次执行),得到 3 4 再再举一个 console.log(1);
console.log(2);
setTimeout(function(){
console.log(3);
setTimeout(function(){
console.log(6);
})
})
setTimeout(function(){
console.log(4);
setTimeout(function(){
console.log(7);
})
})
console.log(5)
复制代码
同样,先执行栈里的同步代码 1 2 5. 再同样,最外层的settimeout会放在队列里,当栈里面执行完成以后,放在栈中执行,3 4。 而嵌套的2个settimeout,会放在一个新的队列中,去执行 6 7. 再再再看一个 console.log(1);
console.log(2);
setTimeout(function(){
console.log(3);
setTimeout(function(){
console.log(6);
})
},400)
setTimeout(function(){
console.log(4);
setTimeout(function(){
console.log(7);
})
},100)
console.log(5)
复制代码
如上:这里的顺序是1,2,5,4,7,3,6。也就是只要两个set时间不一样的时候 ,就set时间短的先走完,包括set里面的回调函数,再走set时间慢的。(因为只有当时间到了的时候,才会把set放到队列里面去) setTimeout(function(){
console.log('setTimeout')
},0)
for(var i = 0;i<10;i++){
console.log(i)
}
复制代码
这个demo的结果是 0 1 2 3 4 5 6 7 8 9 setTimeout 所以,得出结论,永远都是栈里的代码先行执行 ,再从队列中依次读事件,加入栈中执行
stack(栈)里面都走完之后,就会依次读取任务队列,将队列中的事件放到执行栈中依次执行,这个时候栈中又出现了事件,这个事件又去调用了WebAPIs里的异步方法,那这些异步方法会在再被调用的时候放在队列里,然后这个主线程(也就是stack)执行完后又将从任务队列中依次读取事件,这个过程是循环不断的。
再回到我们的第一个 console.log(1)
let promise = new Promise(function(resolve,reject){
console.log(3)
resolve(100)
}).then(function(data){
console.log(100)
})
setTimeout(function(){
console.log(4);
})
console.log(2)
复制代码
上面这个demo的结果值是 1 3 2 100 4 setTimeout是宏任务,而Promise.then是微任务 这里的new Promise()是同步的,所以是立即执行的。
这就要引入一个新的话题宏任务 和微任务 (面试也会经常提及到) 宏任务和微任务 参考 Tasks, microtasks, queues and schedules(https:// jakearchibald.com/2015/ tasks-microtasks-queues-and-schedules/?utm_source=html5weekly
概念:微任务和宏任务都是属于队列,而不是放在栈中
一个新的 console.log('1');
setTimeout(function() {
console.log('setTimeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise1');
}).then(function() {
console.log('promise2');
});
console.log('2');
复制代码
1 2 promise1 promise2 setTimeout 宏任务(task) 浏览器为了能够使得JS内部宏任务与DOM任务能够有序的执行,会在一个task执行结束后,在下一个 task 执行开始前,对页面进行重新渲染 (task->渲染->task->…) 鼠标点击会触发一个事件回调,需要执行一个宏任务,然后解析HTMl。但是,setTimeout不一样 ,setTimeout的作用是等待给定的时间后为它的回调产生一个新的宏任务 。这就是为什么打印‘setTimeout ’在‘promise1 , promise2 ’之后。因为打印‘promise1 , promise2 ’是第一个宏任务里面的事情,而‘setTimeout ’是另一个新的独立的 任务里面打印的。
微任务 (Microtasks) 微任务通常来说就是需要在当前 task 执行结束后立即执行的任务 比如对一系列动作做出反馈,或者是需要异步的执行任务而又不需要分配一个新的 task,这样便可以减小一点性能的开销 。只要执行栈中没有其他的js代码正在执行且每个宏任务执行完,微任务队列会立即执行。如果在微任务执行期间微任务队列加入了新的微任务,会将新的微任务加入队列尾部,之后也会被执行。微任务包括了mutation observe的回调还有接下来的例子promise的回调 。
一旦一个pormise有了结果,或者早已有了结果(有了结果是指这个promise到了fulfilled或rejected状态),他就会为它的回调产生一个微任务,这就保证了回调异步的执行即使这个promise早已有了结果。所以对一个已经有了结果的**promise调用.then()**会立即产生一个微任务。这就是为什么‘promise1’,'promise2’会打印在‘script end’之后,因为所有微任务执行的时候,当前执行栈的代码必须已经执行完毕。‘promise1’,'promise2’会打印在‘setTimeout’之前是因为所有微任务总会在下一个宏任务之前全部执行完毕。
还是 <div class="outer">
<div class="inner"></div>
</div>
复制代码
// elements
var outer = document.querySelector('.outer');
var inner = document.querySelector('.inner');
//监听element属性变化
new MutationObserver(function() {
console.log('mutate');
}).observe(outer, {
attributes: true
});
// click listener…
function onClick() {
console.log('click');
setTimeout(function() {
console.log('timeout');
}, 0);
Promise.resolve().then(function() {
console.log('promise');
});
outer.setAttribute('data-random', Math.random());
}
//
inner.addEventListener('click', onClick);
outer.addEventListener('click', onClick);
复制代码
click promise mutate click promise mutate (2) timeout 很好的解释了,setTimeout会在微任务(Promise.then、MutationObserver.observe)执行完成之后,加入一个新的宏任务中
多看一些 console.log(1);
setTimeout(function(){
console.log(2);
Promise.resolve(1).then(function(){
console.log('promise1')
})
})
setTimeout(function(){
console.log(3)
Promise.resolve(1).then(function(){
console.log('promise2')
})
})
setTimeout(function(){
console.log(4)
Promise.resolve(1).then(function(){
console.log('promise3')
})
})
复制代码
1 2 promise1 3 promise2 4 promise3 console.log(1);
setTimeout(function(){
console.log(2);
Promise.resolve(1).then(function(){
console.log('promise1')
setTimeout(function(){
console.log(3)
Promise.resolve(1).then(function(){
console.log('promise2')
})
})
})
})
复制代码
1 2 promise1 3 promise2 总结回顾
堆:
存储引用数据类型
按引用访问
存储的值大小不定,可动态调整
主要用来存放对象
空间大,但是运行效率相对较低
无序存储,可根据引用直接获取
广而告之 本文发布于薄荷前端周刊 ,欢迎Watch & Star ★,转载请注明出处。
作者:薄荷前端https:// juejin.im/post/5b1deac0 6fb9a01e643e2a95 觉得有用的话就点个赞吧,让更多人看到!