Linux grep 命令
2015-07-13 创建
1、概述
使用正则表达式搜索文本,并把匹 配的行打印出来。
2、命令格式
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
3、常用命令参数
匹配选择:
-E, --extended-regexp 使用扩展正则表达式 【不用使用 \ 了】
-F, --fixed-strings 相当于fgrep 不支持正则表达式
匹配控制:
-e PATTERN, --regexp=PATTERN 这可以用于多个搜索模式指定,或用连字符(-)开始保护模式。
[root@mode-6 day03]# cat grepTest2
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 6 - reboot (Do NOT set initdefault to this)
[root@mode-6 day03]# grep -e 'multiuser' grepTest2
# 3 - Full multiuser mode
[root@mode-6 day03]# grep -e 'multiuser' -e 'initdefault' grepTest2 # 多个正则匹配
# 0 - halt (Do NOT set initdefault to this)
# 3 - Full multiuser mode
# 6 - reboot (Do NOT set initdefault to this)
-i, --ignore-case 忽略大小写
-x, --line-regexp 整行匹配
-y "-i" 的同义词
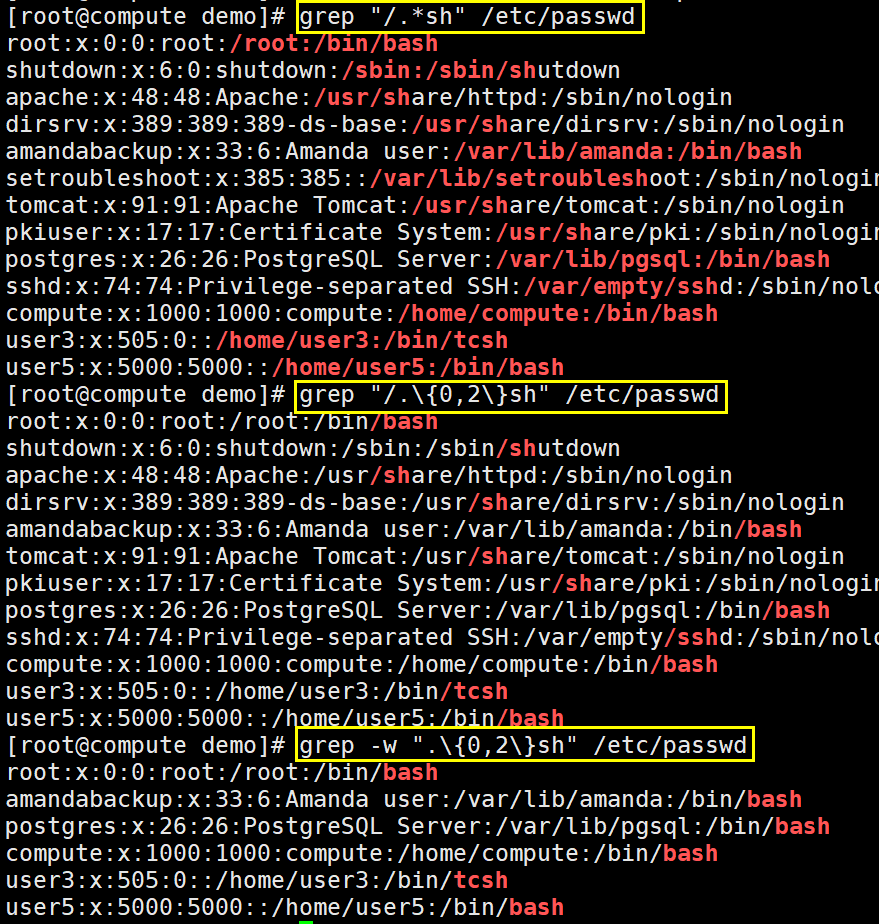
-w, --word-regexp 单词匹配
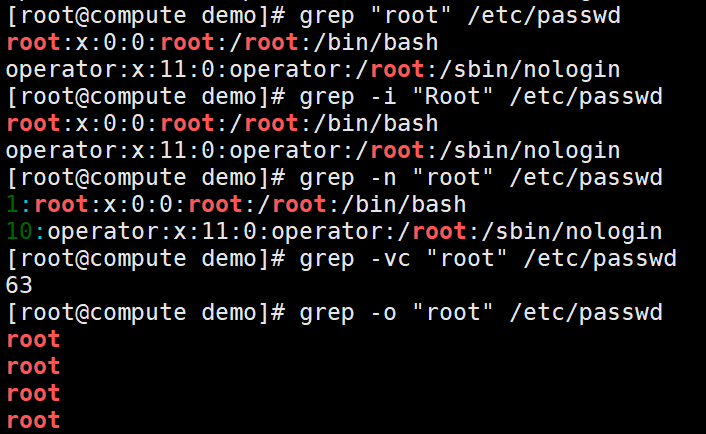
-v, --invert-match 显示没有被模式匹配到的行,匹配的行不显示
[oldboy@moban ~]$ grep --color -v "nologin" /etc/passwd
root:x:0:0:root:/root:/bin/bash
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
oldboy:x:500:500::/home/oldboy:/bin/bash
hive:x:501:501::/home/hive:/bin/bash
kkk:x:502:502::/home/kkk:/bin/bash
通用输出控制:
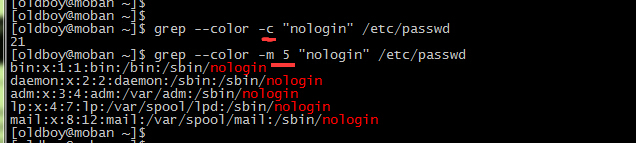
-c, --count 得到匹配行数。示例:
[oldboy@moban ~]$ grep -c -v "nologin" /etc/passwd
7
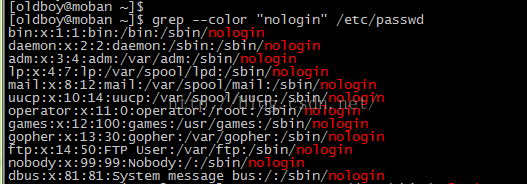
--color[=WHEN], --colour[=WHEN] 匹配处,高亮显示【默认红色字体】。示例:
[oldboy@moban ~]$ grep --color "nologin" /etc/passwd
-L, --files-without-match 查看那些文件没有被匹配。【通常针对多个文件匹配时】
-l, --files-with-matches 查看那些文件是由匹配的。【通常针对多个文件匹配时】【小写字母 L】

-m NUM, --max-count=NUM 匹配多少行;如果NUM超过匹配行数,那么显示所有匹配行。示例:
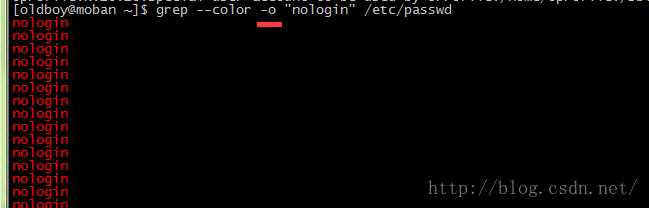
-o, --only-matching 只显示被模式匹配到的字符串。示例:
输出行前缀控制:
-b, --byte-offset 在显示符合样式的那一行之前,标示出该行第0个字符的偏移。示例:

-H, --with-filename 在显示符合样式的那一行之前,显示该行所属的文件名称

-n, --line-number 显示匹配行所在的行号。
上下文控制:
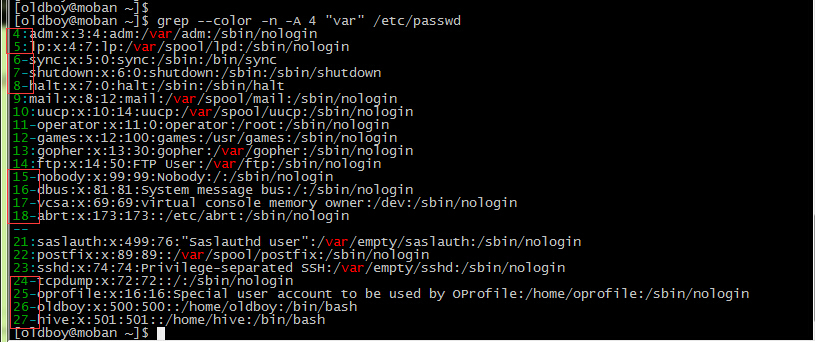
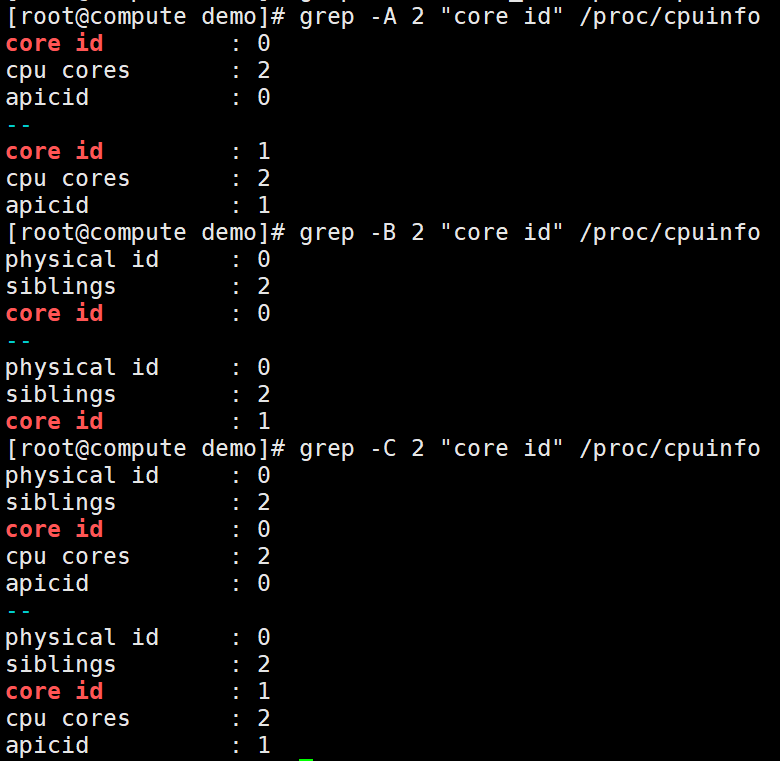
-A NUM, --after-context=NUM 显示匹配行,和之后的NUM行数据。示例:
-B NUM, --before-context=NUM 显示匹配行,和之前的NUM行数据。
-C NUM, -NUM, --context=NUM 显示匹配行,和之前以及之后NUM行数据。
4、正则表达式
基本正则表达式: 默认匹配次数:贪婪模式,尽可能多的去匹配
1)元字符:
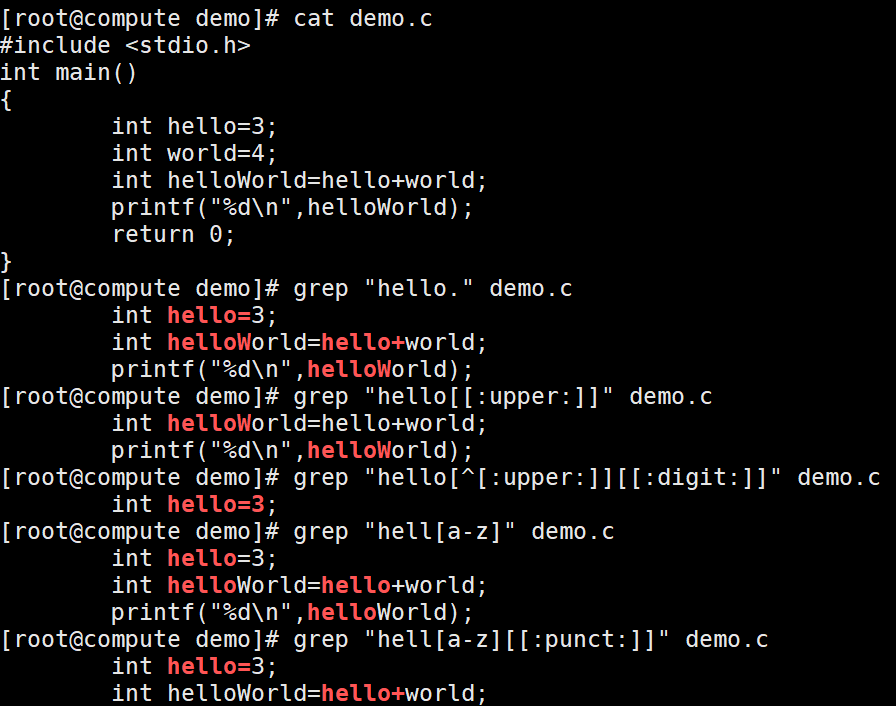
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符 [0-9],[a-z],[abc]
[^] 匹配指定范围外的任意单个字符
2)字符集合:
纯数字 [[:digit:]]或[0-9]
小写字母 [[:lower:]]或[a-z] 大写字母 [[:upper:]]或[A-Z]
大小写字母 [[:alpha:]]或[a-zA-Z] 数字加字母 [[:alnum:]]或[0-9a-zA-Z]
空白字符 [[:space:]] 非空白字符[^[:space:]]
标点符号 [[:punct:]]
【可以通过man tr查询这些字符集合】
3)匹配次数(贪婪模式):
* 匹配其前面的字符任意次 【0次或多次】
.* 任意长度的任意字符
\. 表示.本身 \逃逸符
\? 匹配其前面的字符0次或1次
x\{m\} 匹配其前面的字符“x”m次(精确匹配)
x\{m,\} 匹配其前面的字符“x”至少m次 【\{1,\} 至少一次,多了不限】
x\{m,n\}:匹配其前面的字符“x”至少m次,至多n次 【\{0,3\} 最多3次,少了不限】
4)位置锚定:
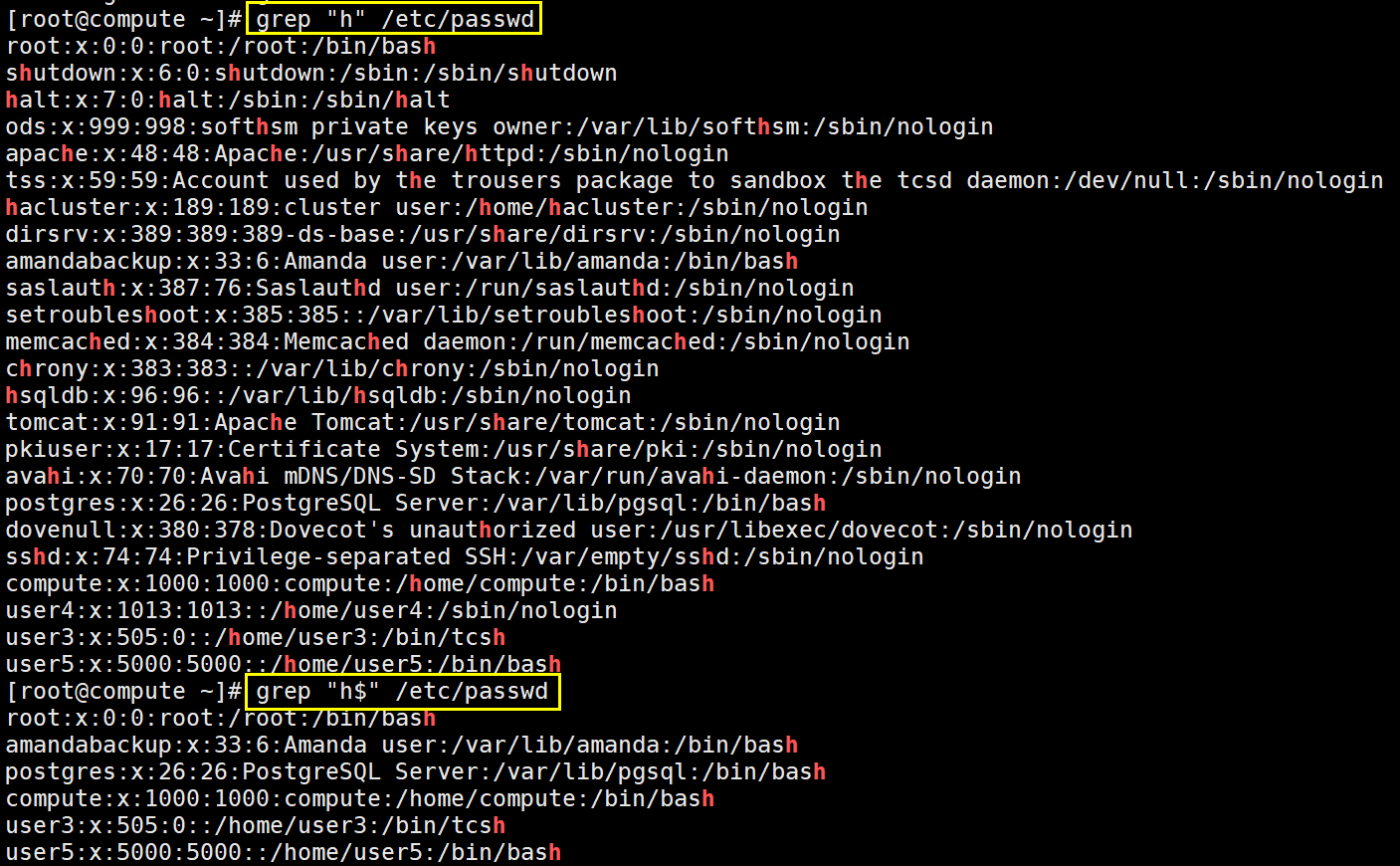
^ 锚定行首,此字符后面的任意内容必须出现在行首 【# grep '^r..t' /etc/passwd】
$ 锚定行尾,此字符前面的任意内容必须出现在行尾【# grep 'login$' /etc/passwd】
^$ 空白行【# grep '^$' /etc/inittab 】
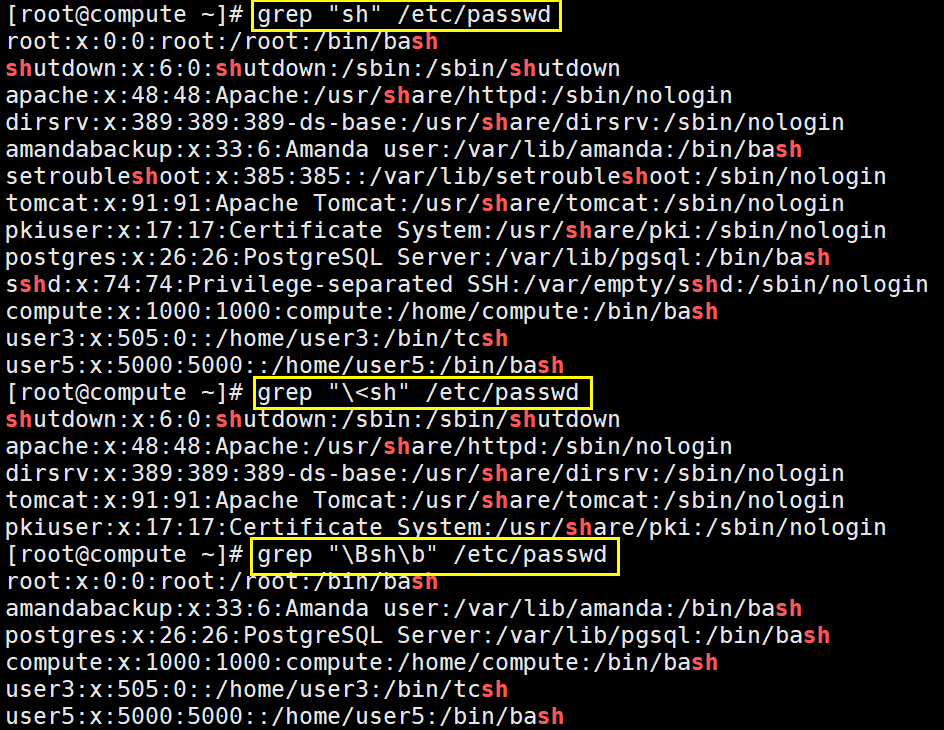
\<或\b 锚定词首,其后面的任意字符必须作为"单词的"首部出现 【# grep "\<root" test2.txt】
\>或\b 锚定词尾,其前面的任意字符必须作为"单词的"尾部出现【# grep "root\>" test2.txt】
\<xxx\>或\bxxx\b 锚定单词例如 \<root\>
5)分组: \(\) 后向引用
\(ab\)* # grep "\(b\)*" test.txt
\1 引用第一个左括号以及与之对应的右括号所包括的所有内容
\2 引用第二个左括号以及与之对应的右括号所包括的所有内容
\3 引用第三个左括号以及与之对应的右括号所包括的所有内容
扩展正则表达式:
+ 匹配其前面的字符至少1次 类似:\{1,\}
? 匹配紧挨在其前面的字符0次或1次 类似:\? 【不需要下斜线 \?】
{m,n} 匹配前面字符至少m次至多n次 {1,}表示1至无限 {0,3}表示0-3 【不需要下斜线 \{\}】
() 分组 \1, \2, \3, ... 【不需要下斜线
】
| 或者 【C|cat: C或cat # grep -E "C|cat" test4.txt 】 (C|c)at: Cat或cat# grep -E "(C|c)at" test4.txt
注意:对于 \<或\b \>或\b 使用扩展正则也不能去掉 \
******* 注意正则表达式和扩展正则表达式的区别
5、常用示例
示例1:
1、以数字结尾
# grep"[[:digit:]]$" /etc/rc.sysinit
# grep"[0-9]$" /etc/rc.sysinit
2、以数字结尾,前面有一个或多个空白字符
# grep"[[:space:]][0-9]$" /etc/rc.sysinit
# grep"[[:space:]]\{1,\}[0-9]$" /etc/rc.sysinit
# grep-E "[[:space:]]+[0-9]$" /etc/rc.sysinit
3、以数字结尾,之前的内容中有一个空格或多个空格
# grep"[[:space:]]\{1,\}.*[0-9]$" /etc/rc.sysinit
# grep-E "[[:space:]]+.*[0-9]$" /etc/rc.sysinit
示例2:
1、有如下文本内容 test1.txt
He love his lover.
She like her lover.
He like his liker.
She love her liker.
She like he.
【请注意他们的不同信息】
# grep "l..e" test1.txt
# grep "l..e.*l..e" test1.txt
# grep "\(l..e\).*\1" test1.txt 【或者:grep -E"(l..e).*\1" test1.txt】
2、对文件/etc/rc.sysinit 文件按照如下规则匹配:
a)结尾是数字 b)结尾的数字在该行中的其他地方有显示
如: wrw35wetgerh3
# grep-E "([0-9]).*\1$" /etc/rc.sysinit
示例3:
1、显示/proc/meminfo文件中以不区分大小的s开头的行.
# grep-i "^s" /proc/meminfo
# grep-E "^(s|S)" /proc/meminfo
# grep-E "^[s|S]" /proc/meminfo
2、显示/etc/passwd中以nologin结尾的行.
# grep"nologin$" /etc/passwd
3、取出默认shell为/sbin/nologin的用户列表。
# grep"/sbin/nologin$" /etc/passwd | cut -d: -f1
4、取出默认shell为bash,且其用户ID号最大用户的用户名和用户编号。
# grep"bash$" /etc/passwd | sort -t: -k3 -nr | head -1 | cut -d: -f1,3
5、显示/etc/inittab中以#开头,且后面跟一个或多个空白字符,而后又跟了任意非空白字符的行.
# grep"^#[[:space:]]\{1,\}[^[:space:]]\{1,\}" /etc/inittab
# grep-E '^#[[:space:]]+[^[:space:]]+' /etc/inittab
6、显示/etc/inittab中包含了:一个数字:(即两个冒号中间一个数字)的行.
# grep-E "(:)[0-9]\1" /etc/inittab
# grep":[0-9]:" /etc/inittab
# grep"\(:[0-9]:\)" /etc/inittab
7、显示/boot/grub/grub.conf文件中以一个或多个空白字符开头的行.
# grep"^[[:space:]]\{1,\}" /boot/grub/grub.conf
# grep-E "^[[:space:]]+" /boot/grub/grub.conf
8、显示/etc/inittab文件中以一个数字开头并以一个与开头数字相同的数字结尾的行.
# grep"^\([0-9]\).*\1$" /etc/inittab
# grep-E "^([0-9]).*\1$" /etc/inittab
示例4:
1、找出某文件中的,1位数,或2位数.
# grep"[0-9]\{1,2\}" /proc/cpuinfo 【错误】
# grep"\<[0-9]\{1,2\}\>" /proc/cpuinfo 【正确】
2、找出ifconfig命令结果中的1-255之间的整数。
3、查找当前系统上名字为hive(必须出现在行首)的用户的帐号的相关信息, 文件为/etc/passwd
# grep"^\<hive\>" /etc/passwd
示例5:
1、分析/etc/inittab文件中如下文本中前两行的特征(每一行中出现在数字必须相同),请写出可以精确找到类似两行的模式:
l1:1:wait:/etc/rc.d/rc1
l3:3:wait:/etc/rc.d/rc3
# grep'^l\([0-9]\):\1.*\1$' /etc/inittab
# grep-E "^l([0-9]):\1.*\1$" /etc/inittab
2、找出/boot/grub/grub.conf文件中1-255之间的数字;
# grep-E '\<([1-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
/boot/grub/grub.conf
3、找出ifconfig中0-255之间的数字;
#ifconfig | egrep --color
'\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
4、找出ifconfig中所有的IP地址
# ifconfig |egrep --color
'(\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>\.){3}\<([0-9]|[1-9][0-9]|1[0-9][0-9]|2[0-4][0-9]|25[0-5])\>'
其他示例:
1、关闭开启多余的启动项【开机启动项优化】
[root@oldboy ~]# chkconfig --list | grep '3:on'
abrt-ccpp 0:off 1:off 2:off 3:on 4:off 5:on 6:off
abrtd 0:off 1:off 2:off 3:on 4:off 5:on 6:off
acpid 0:off 1:off 2:on 3:on 4:on 5:on 6:off
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
blk-availability 0:off 1:on 2:on 3:on 4:on 5:on 6:off
cpuspeed 0:off 1:on 2:on 3:on 4:on 5:on 6:off
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off # 需要
haldaemon 0:off 1:off 2:off 3:on 4:on 5:on 6:off
ip6tables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
irqbalance 0:off 1:off 2:off 3:on 4:on 5:on 6:off
kdump 0:off 1:off 2:off 3:on 4:on 5:on 6:off
lvm2-monitor 0:off 1:on 2:on 3:on 4:on 5:on 6:off
messagebus 0:off 1:off 2:on 3:on 4:on 5:on 6:off
netfs 0:off 1:off 2:off 3:on 4:on 5:on 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off # 需要
postfix 0:off 1:off 2:on 3:on 4:on 5:on 6:off
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off # 需要
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off # 需要
sysstat 0:off 1:on 2:on 3:on 4:on 5:on 6:off # 需要
udev-post 0:off 1:on 2:on 3:on 4:on 5:on 6:off
思路:
1、关闭全部,然后开启需要的
#chkconfig --list | grep '3:on'
#chkconfig --list | grep '3:on' | awk '{print $1}'
#chkconfig --list | grep '3:on' | awk '{print "chkconfig",$1,"off"}'
#chkconfig --list | grep '3:on' | awk '{print "chkconfig",$1,"off"}' | bash # 关闭全部服务
#chkconfig --list | grep '3:on'
#chkconfig --list | grep -E 'crond|network|rsyslog|sshd|sysstat'
#chkconfig --list | grep -E 'crond|network|rsyslog|sshd|sysstat' | awk '{print "chkconfig",$1,"on"}'
#chkconfig --list | grep -E 'crond|network|rsyslog|sshd|sysstat' | awk '{print "chkconfig",$1,"on"}' | bash # 开启指定服务
#chkconfig --list | grep '3:on'
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sysstat 0:off 1:on 2:on 3:on 4:on 5:on 6:off
2、除了需要的,其他的全部关闭【下面是步骤】 推荐使用
#chkconfig --list | grep '3:on'
#chkconfig --list | grep '3:on' | grep -E 'crond|network|rsyslog|sshd|sysstat'
#chkconfig --list | grep '3:on' | grep -Ev 'crond|network|rsyslog|sshd|sysstat'
#chkconfig --list | grep '3:on' | grep -Ev 'crond|network|rsyslog|sshd|sysstat' | awk '{print $1}'
#chkconfig --list | grep '3:on' | grep -Ev 'crond|network|rsyslog|sshd|sysstat' | awk '{print "chkconfig",$1,"off"}'
#chkconfig --list | grep '3:on' | grep -Ev 'crond|network|rsyslog|sshd|sysstat' | awk '{print "chkconfig",$1,"off"}' | bash
#chkconfig --list | grep '3:on'
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
rsyslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sysstat 0:off 1:on 2:on 3:on 4:on 5:on 6:off
6、当前命令所在位置和类型
[oldboy@moban ~]$ which grep
/bin/grep
[oldboy@moban ~]$ type grep
grep is /bin/grep
7、参考文章
每天一个linux命令(39):grep 命令
linux grep命令详解
linux中grep命令
Linux正则表达式语法
来自 https://blog.csdn.net/woshizhangliang999/article/details/46859161/
作为linux中最为常用的三大文本(awk,sed,grep)处理工具之一,掌握好其用法是很有必要的。
首先谈一下grep命令的常用格式为:grep [选项] ”模式“ [文件]
grep家族总共有三个:grep,egrep,fgrep。
常用选项:
-E :开启扩展(Extend)的正则表达式。
-i :忽略大小写(ignore case)。
-v :反过来(invert),只打印没有匹配的,而匹配的反而不打印。
-n :显示行号
-w :被匹配的文本只能是单词,而不能是单词中的某一部分,如文本中有liker,而我搜寻的只是like,就可以使用-w选项来避免匹配liker
-c :显示总共有多少行被匹配到了,而不是显示被匹配到的内容,注意如果同时使用-cv选项是显示有多少行没有被匹配到。
-o :只显示被模式匹配到的字符串。
--color :将匹配到的内容以颜色高亮显示。
-A n:显示匹配到的字符串所在的行及其后n行,after
-B n:显示匹配到的字符串所在的行及其前n行,before
-C n:显示匹配到的字符串所在的行及其前后各n行,context
模式部分:
1、直接输入要匹配的字符串,这个可以用fgrep(fast grep)代替来提高查找速度,比如我要匹配一下hello.c文件中printf的个数:fgrep -c "printf" hello.c
2、使用基本正则表达式,下面谈关于基本正则表达式的使用:
匹配字符:
. :任意一个字符。
[abc] :表示匹配一个字符,这个字符必须是abc中的一个。
[a-zA-Z] :表示匹配一个字符,这个字符必须是a-z或A-Z这52个字母中的一个。
[^123] :匹配一个字符,这个字符是除了1、2、3以外的所有字符。
对于一些常用的字符集,系统做了定义:
[A-Za-z] 等价于 [[:alpha:]]
[0-9] 等价于 [[:digit:]]
[A-Za-z0-9] 等价于 [[:alnum:]]
tab,space 等空白字符 [[:space:]]
[A-Z] 等价于 [[:upper:]]
[a-z] 等价于 [[:lower:]]
标点符号 [[:punct:]]
匹配次数:
\{m,n\} :匹配其前面出现的字符至少m次,至多n次。
\? :匹配其前面出现的内容0次或1次,等价于\{0,1\}。
* :匹配其前面出现的内容任意次,等价于\{0,\},所以 ".*" 表述任意字符任意次,即无论什么内容全部匹配。
位置锚定:
^ :锚定行首
$ :锚定行尾。技巧:"^$"用于匹配空白行。
\b或\<:锚定单词的词首。如"\blike"不会匹配alike,但是会匹配liker
\b或\>:锚定单词的词尾。如"\blike\b"不会匹配alike和liker,只会匹配like
\B :与\b作用相反。
分组及引用:
\(string\) :将string作为一个整体方便后面引用
\1 :引用第1个左括号及其对应的右括号所匹配的内容。
\2 :引用第2个左括号及其对应的右括号所匹配的内容。
\n :引用第n个左括号及其对应的右括号所匹配的内容。

3、扩展的(Extend)正则表达式(注意要使用扩展的正则表达式要加-E选项,或者直接使用egrep):
匹配字符:这部分和基本正则表达式一样
匹配次数:
* :和基本正则表达式一样
? :基本正则表达式是\?,二这里没有\。
{m,n} :相比基本正则表达式也是没有了\。
+ :匹配其前面的字符至少一次,相当于{1,}。
位置锚定:和基本正则表达式一样。
分组及引用:
(string) :相比基本正则表达式也是没有了\。
\1 :引用部分和基本正则表达式一样。
\n :引用部分和基本正则表达式一样。
或者:
a|b :匹配a或b,注意a是指 | 的左边的整体,b也同理。比如 C|cat 表示的是 C或cat,而不是Cat或cat,如果要表示Cat或cat,则应该写为 (C|c)at 。记住(string)除了用于引用还用于分组。
注1:默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。
注2:所有的正则字符,如 [ 、* 、( 等,若要搜索 * ,而不是想把 * 解释为重复先前字符任意次,可以使用 \* 来转义。
下面用一个练习来结束本次grep的学习:
在网络配置文件 /etc/sysconfig/network-scripts/ifcfg-ens33 中检索出所有的 IP
1、检索出 0-255的范围
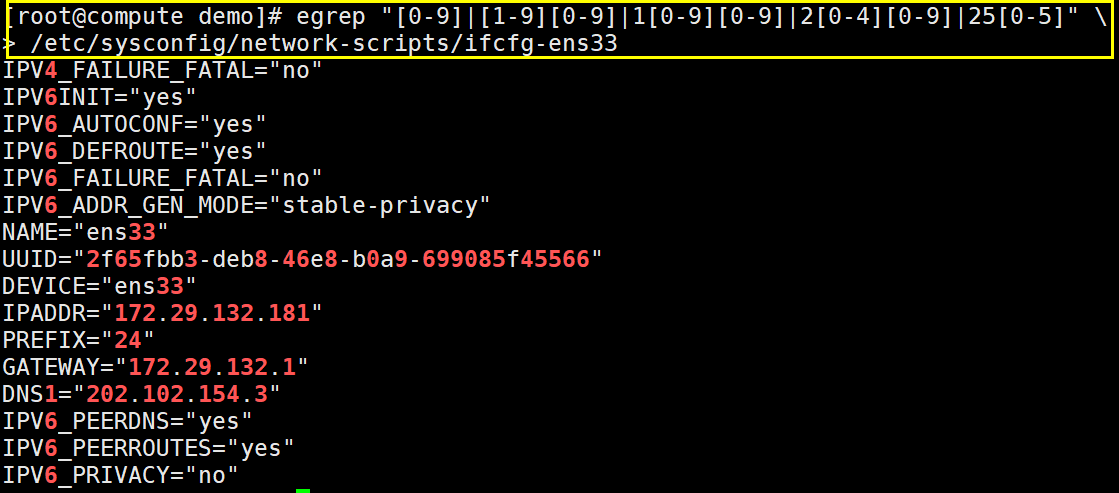
2、由0-255的数字组合成IP

3、简化
