You are here
Redis 怎么做消息队列? 不建议redis 消息订阅发布 不建议 publish subscribe pub / sub
有个想法,用两个服务器,node处理请求,把数据全部push到 redis缓存队列中,另一个php服务器不断的pop这个队列里的数据然后与mysql交互做持久化。大家觉得这么做怎么样?
作者:翁伟
链接:https://www.zhihu.com/question/20795043/answer/345073457来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
不要使用redis去做消息队列,这不是redis的设计目标。
但实在太多人使用redis去做去消息队列,redis的作者看不下去,另外基于redis的核心代码,另外实现了一个消息队列disque: antirez/disque
部署、协议等方面都跟redis非常类似,并且支持集群,延迟消息等等。
disque亦会成为redis 4.2的module:https://gist.github.com/antirez/a3787d538eec3db381a41654e214b31d
也就是说,成为redis内置的消息队列。
1. Redis自带的PUB/SUB机制,即发布-订阅模式。这种模式生产者(producer)和消费者(consumer)是1-M的关系,即一条消息会被多个消费者消费,当只有一个消费者时即可以看做一个1-1的消息队列,但这种方式并不适合题主的场景。首先,数据可靠性的无法保障,题主的数据最终需要落库,如果消息丢失、Redis宕机部分数据没有持久化甚至突然的网络抖动都可能带来数据的丢失,应该是无法忍受的。其次,扩展不灵活,没法通过多加consumer来加快消费的进度,如果前端写入数据太多,同步会比较慢,数据不同步的状态越久,风险越大,当然可以通过channel拆分的方式来解决,虽然不灵活,但可以规避。这种方案更适合于对数据可靠性要求不高,比如一些统计日志打点。
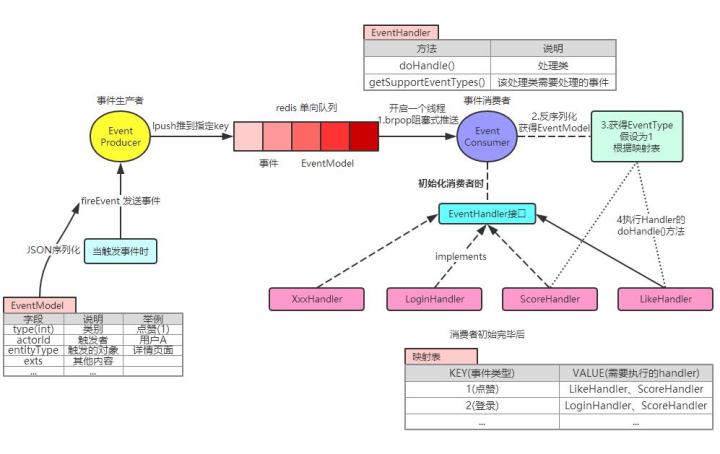
2. Redis的PUSH/POP机制,利用的Redis的列表(lists)数据结构。比较好的使用模式是,生产者lpush消息,消费者brpop消息,并设定超时时间,可以减少redis的压力。这种方案相对于第一种方案是数据可靠性提高了,只有在Redis宕机且数据没有持久化的情况下丢失数据,可以根据业务通过AOF和缩短持久化间隔来保证很高的可靠性,而且也可以通过多个client来提高消费速度。但相对于专业的消息队列来说,该方案消息的状态过于简单(没有状态),且没有ack机制,消息取出后消费失败依赖于client记录日志或者重新push到队列里面。
最后再来看题主的需求,是希望先写Redis,再异步同步到mysql里面,期望数据的最终一致性。这样带来的好处是前端写的请求飞速啊(不用落盘当然快),问题是很复杂,而且不太合理。假设是合理的话,就应该选择一个更可靠的消息中间件,比如Redis作者开源的Disque,或者阿里开源RocketMQ,以及基于Golang的nsq等,Redis更适合用来存数据。
为什么说题主的需求不合理?
类似于这种先写缓存再同步到DB的,目的是为了减少DB压力,提升前端API性能。题主的方案虽然能做到这两点,但忽略了根本的一点:数据不管存到哪里,都是用来访问(使用)的。但在题主的方案里,写入Redis的数据除了同步到DB里,不接任何访问量,并没有什么卵用,最后DB读的压力上来了,还得把数据重新LOAD回Redis里面,得不偿失。
什么样的架构更合理?
只简单说一下。
异步写入,在百度、58同城使用很多,基本的架构是先抽象出对象访问层(或者只是缓存层),对外屏蔽数据来源(Redis、mysql、others)。对象访问层对于某类数据的格式是定义好的,写的请求来了直接写入缓存(Redis),这样前端的读请求就直接读缓存了,这样存入的数据就有意义(当然了,接了大大的读的量啊)。然后是数据落地(最终一致性问题),简单的可以读RDB文件(实时性不高),复杂一点的可以实现Redis的主从同步协议(实时性高于前一种)。第一种简单,效率低,第二种复杂,效率高。
从Redis谈起(三)—— Redis和消息中间件 这边文章比较详细得讲解了Redis和消息中间件
谢谢,希望对大家有帮助。
redis 做消息队列不合适,像 kafka 这种消息队列的主要场景是跨业务同步消息,有一定的保序、at-least-once 之类的 guarantee 要求。
不过 redis 做 beanstalkd 这样的任务队列是 production ready 而且 battle tested 的,期望通过任务队列做到在业务内快速扩异步任务 worker,加上 buried 失败任务登记允许重试,一定的容量能够缓冲异步 worker 故障出现的任务积压。
这时需要注意的是,业务上避免过度复用一个 redis。既用它做缓存、做计算,还拿它做任务队列,这样不好。
利益相关:经常拿 Redis 当 Celery Broker
Redis 不适合拿来当消息队列,一些基本的要求:顺序保证,消息至少到达一次,持久化等等特性都完全没有保证。如果是内部系统拿来跑一些异步任务并且对可用性和性能要求都不高的情况下,不失是一种省事方便的选择。题主描述的场景是正儿八经的业务,还是选真正是 mq 比较好。redis本身就支持pub/sub模式,可以作为消息队列处理,参见 Command reference
按题主的场景,需要配置redis的持久化保存,否则可能会出现数据没有保存到mysql中的情形。redis 的 list结构,可满足你最基本的 push/pop
然而 比较复杂一点的需求,比如插队、批量获取、查找 等就无法实现了,不过可以使用 zset()有序集合)加一些代码逻辑实现。
毕竟zset 没有pop ,它只能 获取一个元素+删除该元素 两步操作,并发下很难保证原子性。
具体做法可参考一个简单例子:https://github.com/liukelin/php_task_queue它里面的关于redis队列消费方法
redis当然可以封装成队列。但如果这样讲,文件也可以做队列(kafka就是这么干的);数据库也可以做队列;管道也可以做队列;ZeroMQ也可以做队列……
我感觉题主的需求描述的比较模糊。
这个队列到底是不是生产用;如果是,要不要保证一致性。(比如用户秒杀下单)。如果是的话,光用redis是远远不够的,你必须花大力气做一致性补偿和异步幂等的工作,保证能实现exactly once语义。如果这样的话,就不如用一个正经的MQ来做更实际。RabbitMQ,nsq,kafka等都可以。
如果是生产用,但是可以容忍丢东西(比如log收集),那么也有现成的方案,fluentd,logstash……
实际上redis并不适合任何有保障数据持久性的场景。它适合做cache,不重要的存储,或者是可以反复重来的批处理计算任务的临时存储等。
当然,如果是自己玩,那么可以随意写。但记得和已有的队列系统的设计和实现做比较,了解一个真正的队列系统为什么那么复杂。相信会有不少收获。
2018年3月19日更新
有知友表示不理解“真正的队列“的含义,所以在这篇文章中阐述了一下观点:你对Redis的使用靠谱吗?
Redis 消息队列介绍 查看详情:Redis 消息队列介绍-博客-云栖社区-阿里云
Redis的消息队列使用简单,没有什么配置,比ActiveMQ要轻量级太多,当然功能也比较简单,如果只需要简单的订阅以及发布,可以考虑使用它。
订阅操作
命令为:subscribe [channel] [channel] ..,如【代码1】所示,即成功订阅频道[redis.blog]。
发布操作
命令为publish [channel] [message],如【代码2】所示,【图1】为订阅的客户端展示效果。 【代码1】:
subscribe "redis. blog"
【代码2】
publish "redis.blog" "hello redis"
【图1】
退订操作
命令为:unsubscribe [channel] [channel] ..,如【代码3】所示。 【代码3】
unsubscribe "redis.blog"
模式订阅
命令为:psubscribe [pattern] [pattern]...,如【代码4】所示,如果发布的消息符合当前订阅的模式,亦会收到消息通知,如【图2】所示。 【代码4】
psubscribe "redis.*"
【图2】
模式退订 命令为:punsubscribe [pattern] [pattern]...,如【代码5】所示。 【代码5】
punsubscribe "redis.*"
数据结构 关于频道以及模式,redis通过两个struct实现,在redisServer中是如下定义的:
struct rediServer{
dict *pubsub_channels;
list *pubsub_patterns;
}
频道是一个dict,pubsub_channels中key为频道名称,value为一个list,list中存储了所有订阅当前频道的client机器; 订阅:如果当前频道还不存在,则subscribe操作即为一次dictAdd操作,如果存在,则相当于将当前的client append到当前channel对应的value list中; 退订:从dict中get(channel)获得list,从list中删除当前client,如果删除后list为空,则表示当前频道已经没有订阅者了,此时将会删除当前channel。
模式是一个list,list中每个node为一个pubsubPattern结构,定义如下:
typedef struct pubsubPattern{
redisClient *client;
robj *pattern;
}
订阅模式:即是在当前list队尾插入一个pubsubPattern; 退订模式:则是遍历list删除匹配节点的过程。 即使不同client订阅同一个模式,也是两个不同的node,或者同一个client订阅2个不同模式,亦为两个node,这一点从pubsubPattern的数据结构上能看出来。
发送消息 发布一条信息,redis服务器会执行2个操作:
将消息发送给相应频道的所有订阅者,具体操作为: 以当前频道为key,在当前pubsub_channels字典中找到对应的value,value为一个订阅者list,遍历该list,将消息发送给所有的订阅者;
将消息发送给与当前频道相匹配的所有模式,具体操作为: 以当前频道为key,在当前pubsub_patterns列表中遍历所有节点,如果某个节点(pubsubPattern)的pattern值和key匹配,则将消息发送给当前节点的client,遍历结束为止。
另外的三个命令
pubsub channels:查看当前所有频道;也可以使用通配,返回所有匹配的平道(pubsub channels “redis.*");
pubsub numsub: 接收任意多个频道作为输入参数,返回这些频道的订阅者数量;
pubsub numpat:返回服务器当前被订阅模式的数量;
至于如何将发布的消息及时反馈给所有订阅者,redis是通过服务器的文件事件来操作的,不单单是消息队列功能,所有的get,set操作都是通过文件事件(file event)来驱动的。
原文链接 :Redis设计思路学习与总结 - 腾云阁
全文:
宋增宽,腾讯工程师,16年毕业加入腾讯,从事海量服务后台设计与研发工作,现在负责QQ群后台等项目,喜欢研究技术,并思考技术演变,专注于高并发业务架构的设计与性能优化。
下半年利用空余时间研究和分析了部分Redis源码,本文从网络模型、数据结构和内存管理、持久化和多机协作四个角度对redis的设计思路进行了分析,若有不正确之处,希望各路大神指出。
Redis是业界普遍应用的缓存组件,研究一个组件框架,最直观的办法就是从应用方的角度出发,将每个步骤的考虑一番,从这些步骤入手去研究往往能够最快的体会到一个组件框架的设计哲学。以Redis为例,每当发起一条请求时,redis是如何管理管理网络请求,收到请求后又是通过什么样的数据结构进行组织并操作内存,这些数据又是如何dump到磁盘实现持久化,再到多机环境下如何同步和保证一致性……本文就是从网络模型、数据结构设计与内存管理、持久化方法和多机四个角度简要描述了redis的设计和自己的一点体会。
一.网络模型
Redis是典型的基于Reactor的事件驱动模型,单进程单线程,高效的框架总是类似的。网络模型与spp的异步模型几乎一致。
Redis流程上整体分为接受请求处理器、响应处理器和应答处理器三个同步模块,每一个请求都是要经历这三个部分。
Redis集成了libevent/epoll/kqueue/select等多种事件管理机制,可以根据操作系统版本自由选择合适的管理机制,其中libevent是最优选择的机制。
Redis的网络模型有着所有事件驱动模型的优点,高效低耗。但是面对耗时较长的操作的时候,同样无法处理请求,只能等到事件处理完毕才能响应,之前在业务中也遇到过这样的场景,删除redis中全量的key-value,整个操作时间较长,操作期间所有的请求都无法响应。所以了解清楚网络模型有助于在业务中扬长避短,减少长耗时的请求,尽可能多一些简单的短耗时请求发挥异步模型的最大的威力,事实上在Redis的设计中也多次体现这一点。
二.数据结构和内存管理
1.字符串
1.1 结构
Redis的字符串是对C语言原始字符串的二次封装,结构如下:
struct sdshdr {
long len;
long free;
char buf[];
};
可以看出,每当定义一个字符串时,除了保存字符的空间,Redis还分配了额外的空间用于管理属性字段。
1.2 内存管理方式
动态内存管理方式,动态方式最大的好处就是能够较为充分的利用内存空间,减少内存碎片化,与此同时带来的劣势就是容易引起频繁的内存抖动,通常采用“空间预分配”和“惰性空间释放”两种优化策略来减少内存抖动,redis也不例外。
每次修改字符串内容时,首先检查内存空间是否符合要求,否则就扩大2倍或者按M增长;减少字符串内容时,内存并不会立刻回收,而是按需回收。
关于内存管理的优化,最基本的出发点就是浪费一点空间还是牺牲一些时间的权衡,像STL、tcmalloc、protobuf3的arena机制等采用的核心思路都是“预分配迟回收”,Redis也是一样的。
1.3 二进制安全
判断字符串结束与否的标识是len字段,而不是C语言的'\0',因此是二进制安全的。 放心的将pb序列化后的二进制字符串存入redis。 简而言之,通过redis的简单封装,redis的字符串的操作更加方便,性能更友好,并且屏蔽了C语言字符串的一些需要用户关心的问题。
2.字典(哈希)
字典的底层一定是hash,涉及到hash一定会涉及到hash算法、冲突的解决方法和hash表扩容和缩容。
2.1 hash算法
Redis使用的就是常用的Murmurhash2,Murmurhash算法能够给出在任意输入序列下的散列分布性,并且计算速度很快。之前做共享内存的Local-Cache的需求时也正是利用了Murmurhash的优势,解决了原有结构的hash函数散列分布性差的问题。
2.2 hash冲突解决方法
链地址法解决hash冲突,通用解决方案没什么特殊的。多说一句,如果选用链地址解决冲突,那么势必要有一个散列性非常好的hash函数,否则hash的性能将会大大折扣。Redis选用了Murmurhash,所以可以放心大胆的采用链地址方案。
2.3 hash扩容和缩容
维持hash表在一个合理的负载范围之内,简称为rehash过程。 rehash的过程也是一个权衡的过程,在做评估之前首先明确一点,不管中间采用什么样的rehash策略,rehash在宏观上看一定是:分配一个新的内存块,老数据搬到新的内存块上,释放旧内存块。 老数据何时搬?怎么搬?就变成了一个需要权衡的问题。 第一部分的网络模型上明确的指出Redis的事件驱动模型特点,不适合玩长耗时操作。如果一个hashtable非常大,需要进行扩容就一次性把老数据copy过去,那就会非常耗时,违背事件驱动的特点。所以Redis依旧采用了一种惰性的方案: 新空间分配完毕后,启动rehashidx标识符表明rehash过程的开始;之后所有增删改查涉及的操作时都会将数据迁移到新空间,直到老空间数据大小为0表明数据已经全部在新空间,将rehashidx禁用,表明rehash结束。 将一次性的集中问题分而治之,在Redis的设计哲学中体现的淋漓尽致,主要是为了避免大耗时操作,影响Redis响应客户请求。
3.整数集合
变长整数存储,整数分为16/32/64三个变长尺度,根据存入的数据所属的类型,进行规划。 每次插入新元素都有可能导致尺度升级(例如由16位涨到32位),因此插入整数的时间复杂度为O(n)。这里也是一个权衡,内存空间和时间的一个折中,尽可能节省内存。
4.跳跃表
Redis的skilplist和普通的skiplist没什么不同,都是冗余数据实现的从粗到细的多层次链表,Redis中应用跳表的地方不多,常见的就是有序集合。 Redis的跳表和普通skiplist没有什么特殊之处。
5.链表
Redis的链表是双向非循环链表,拥有表头和表尾指针,对于首尾的操作时间复杂度是O(1),查找时间复杂度O(n),插入时间复杂度O(1)。 Redis的链表和普通链表没有什么特殊之处。
三.AOF和RDB持久化
AOF持久化日志,RDB持久化实体数据,AOF优先级大于RDB。
1.AOF持久化
机制:通过定时事件将aof缓冲区内的数据定时写到磁盘上。
2.AOF重写
为了减少AOF大小,Redis提供了AOF重写功能,这个重写功能做的工作就是创建一个新AOF文件代替老的AOF,并且这个新的AOF文件没有一条冗余指令。(例如对list先插入A/B/C,后删除B/C,再插入D共6条指令,最终状态为A/D,只需1条指令就可以) 实现原理就是读现有数据库的状态,根据状态反推指令,跟之前的AOF无关。同样,为了避免长时间耗时,重写工作放在子进程进行。
3.RDB持久化
SAVE和BGSAVE两个命令都是用于生成RDB文件,区别在于BGSAVE会fork出一个子进程单独进行,不影响Redis处理正常请求。 定时和定次数后进行持久化操作。 简而言之,RDB的过程其实是比较简单的,满足条件后直接去写RDB文件就结束了。
四.多机和集群
1.主从服务器
避免单点是所有服务的通用问题,Redis也不例外。解决单点就要有备机,有备机就要解决固有的数据同步问题。
1.1 sync——原始版主从同步
Redis最初的同步做法是sync指令,通过sync每次都会全量数据,显然每次都全量复制的设计比较消耗资源。改进思路也是常规逻辑,第一次全量,剩下的增量,这就是现在的psync指令的活。
1.2 psync
部分重同步实现的技术手段是“偏移序号+积压缓冲区”,具体做法如下: (1)主从分别维护一个seq,主每次完成一个请求便seq+1,从每同步完后更新自己seq; (2)从每次打算同步时都是携带着自己的seq到主,主将自身的seq与从做差结果与积压缓冲区大小比较,如果小于积压缓冲区大小,直接从积压缓冲区取相应的操作进行部分重同步; (3)否则说明积压缓冲区不能够cover掉主从不一致的数据,进行全量同步。 本质做法用空间换时间,显然在这里牺牲部分空间换回高效的部分重同步,收益比很大。
2.Sentinel
本质:多主从服务器的Redis系统,多台主从上加了管理监控,以保证系统高可用性。
3.集群
Redis的官方版集群尚未在工业界普及起来,下面主要介绍一下集群的管理体系和运转体系。
2.1 slot-集群单位
集群的数据区由slot组成,每个节点负责的slot是在集群启动时分配的。
2.2 客户请求
客户请求时如果相应数据hash后不属于请求节点所管理的slots,会给客户返回MOVED错误,并给出正确的slots。 从这个层面看,redis的集群还不够友好,集群内部的状态必须由客户感知。
2.3 容灾
主从服务器,从用于备份主,一旦主故障,从代替主。
通过Redis的研究,深刻体会到的一点就是:所有设计的过程都是权衡和割舍的过程。同样放到日常的工作和开发中也是如此,一句代码写的好不好,一个模块设计的是否科学,就从速度和内存的角度去衡量看是否需要优化,并去评估每一种优化会收益到什么,同时会损失什么,收益远大于损失的就是好的优化,这样往往对于开发和提升更有针对性,更能提高效率。
class Queue():
def __init__(self, name):
self.name = name
self.redis = RedisEntity()
def put(self, ele):
self.redis.lpush(self.name, json.dumps(ele))
def get(self):
try:
k, v = self.redis.brpop(self.name, timeout=5)
except:
raise exceptions.EOFError
return json.loads(v)
<dependency>
<groupId>com.moilioncircle</groupId>
<artifactId>redis-replicator</artifactId>
<version>2.5.0</version>
</dependency>
选一个基于redis的MQ吧,开源又好用的不少。
像的回答一样,写进来的时候直接写到redis读也交给redis。至于数据同步到mysql计划个时间和方案再批量同步吧。
至于redis的可靠性就是其他问题了…
什么类的数据?
要求不是很高的话可以用logstash
目前官方没有mysql的output plugins
输入源 redis支持lpush和lpop和、pub/sub模式,改改配置文件就行了,不用redis,用nsq、 kafka之类也有对应的插件
输出插件看官方文档,支持mongodb和elasticsearch